- 《重来》(更为简单有效的商业思维)
- 《启示录》(打造用户喜欢的产品)
2017年3月18日星期六
2017年3月10日星期五
2017年3月1日星期三
Distributed System Design
Unix / Linux systems and internals
https://tasteturnpike.blogspot.com/2021/04/database.html
http://tasteturnpike.blogspot.com/2017/09/network.html
https://tasteturnpike.blogspot.com/2017/11/site-reliability-engineering-how-google.html
System Design
https://puncsky.com/hacking-the-software-engineer-interview/?isAdmin=true
https://github.com/checkcheckzz/system-design-interview
http://www.aosabook.org/en/distsys.html
Companies
http://highscalability.com/blog/2015/9/14/how-uber-scales-their-real-time-market-platform.html
https://www.quora.com/What-is-YouTubes-architecture
估算问题Envelope Calculations: http://highscalability.com/blog/2011/1/26/google-pro-tip-use-back-of-the-envelope-calculations-to-choo.html
 Multi-tenant 架构
Multi-tenant 架构

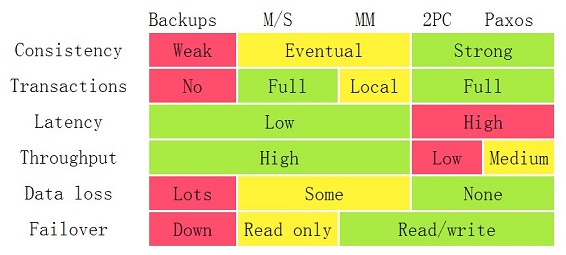
Consistency: All clients see the same most recent write or error
http://tasteturnpike.blogspot.com/2017/09/network.html
https://tasteturnpike.blogspot.com/2017/11/site-reliability-engineering-how-google.html
System Design
https://puncsky.com/hacking-the-software-engineer-interview/?isAdmin=true
https://github.com/checkcheckzz/system-design-interview
http://www.aosabook.org/en/distsys.html
Companies
http://highscalability.com/blog/2015/9/14/how-uber-scales-their-real-time-market-platform.html
https://www.quora.com/What-is-YouTubes-architecture
估算问题Envelope Calculations: http://highscalability.com/blog/2011/1/26/google-pro-tip-use-back-of-the-envelope-calculations-to-choo.html
Design 范式
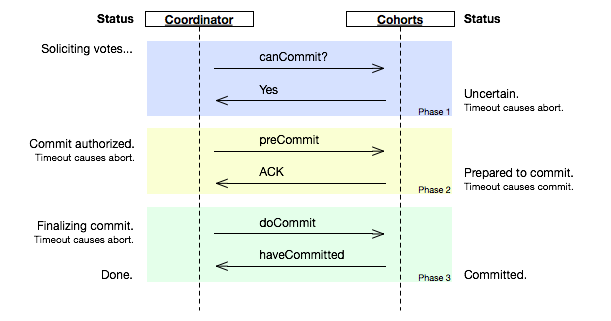
- Compare 2PC to Paxos. What is different? What is similar? Will you ever need both together in a system?
- Raft
- Clock
CockroachDB: The Resilient Geo-Distributed SQL Database
- shared-nothing architecture: all nodes are used for both data storage and computation
- single node is layered architecture:
- SQL: parser, optimizer, SQL execution engine (convert SQL to low-level read write requests to KV store)
- Transactional KV: ensures atomicity of changes spanning multiple KV pairs; isolation guarantee
- Distribution: a monolithic logical key space ordered by key. chunk = Range = 64MB. The Distribution layer is responsible for identifying which Ranges should handle which subset of each query, and routes the subsets accordingly.
- Replication: consensus-based replication
- Storage: RocksDB -> Pebble
- Fault Tolerance and High Availability
- Replication using Raft: Replicas of a Range form a Raft group. Each replica individually applies command. Usually Raft group leader acts as the leaseholder. All writes go through the leaseholder. Leases for user Ranges are tied to the liveness of the node the leaseholder is on. Heartbeat is every 4.5 seconds.
- Membership changes and automatic load rebalancing. Use peer-to-peer gossip protocol to determine node liveness
- Replica placement. Each nodes has its own attributes like capability (CPU, RAM) or locality (country, region)
- Transactions
- Execution at the transaction coordinator: coordinator receives a series of requested KV operations from the SQL layer. Optimization: batch multi-statement SQL transactions to complete with one replication.
- Write Pipelining: if no overlapping, operations on different keys can be "pipelined". if operation depends on earlier in-flight operation, execution must wait for earlier in-flight execution
- Parallel Commits: Naively, needs at least two sequential rounds of consensus before commit??? Optimization: initiate the replication of the staging status in parallel with the verification of the outstanding writes???
- Execution at the leaseholder:
- Acquires latches on the keys and dependencies
- Write operations are replicated. After consensus is reached, each replica applies the command to local storage engine
- Release latches
- Transaction record: A metadata which is a special key stores the current disposition of transaction: pending, staging, committed or aborted
- Concurrency Control: A total ordering of all transactions in the system, representing a serializable execution. Conflicts may require commit timestamp adjustments: The transaction typically tries to prove that its prior reads remain valid at the new timestamp 如果并发transaction撞到一起,则调后以错开它们的timestamp以达到serializable execution。并不需要按照它们出生的时间顺序进行执行,而是尊重它们物理到达时间,先到先执行
- Deadlock: CRDB employs a distributed deadlock-detection algorithm to abort one transaction from a cycle of waiters.
- Write-read conflicts: write在前,read等待完成
- Read-write conflicts: 后头的read先到并执行,write等待并改到read后的时间
- Write-write conflicts: 后头的write先到并执行,前头的write改时间过后头
- Read Refresh: Certain types of conflicts described above require advancing the commit timestamp of a transaction. To maintain serializability, the read timestamp must be advanced to match the commit timestamp
- 个人理解:在并发时不用保证多用户request的实际顺序,而要保证单用户多transaction的顺序: 一个用户的RW到达时变为WR,这时read不能advance,并触发read refresh
- Advancing a transaction’s read timestamp from ta to tb > ta is possible if we can prove that none of the data that the transaction read at ta has been updated in the interval (ta,tb ]. If the data has changed, the transaction needs to be restarted. If no results from the transaction have been delivered to the client, CRDB retries the transaction internally. If results have been delivered, the client is informed to discard them and restart the transaction
- To determine whether the read timestamp can be advanced, CRDB maintains the set of keys in the transaction’s read set (up to a memory budget) This involves re-scanning the read set and checking whether any MVCC values fall in the given interval. This process is equivalent to detecting the rw-antidependencies that PostgreSQL tracks for its implementation of SSI. Similar to PostgreSQL, our implementation may allow false positives (forcing a transaction to abort when not strictly necessary) to avoid the overhead of maintaining a full dependency graph
- Follower Reads: CRDB allows non-leaseholder replicas to serve requests for read-only queries with timestamps sufficiently in the past. Each leaseholder tracks the timestamps of all incoming requests and periodically emits a closed timestamp, the timestamp below which no further writes will be accepted. Every node keeps a record of its latency with all other nodes in the system. When a node in the cluster receives a read request at a sufficiently old timestamp (closed timestamps typically trail current time by ~2 seconds), it forwards the request to the closest node with a replica of the data.
- Clock Synchronization
- Hybrid-Logical Clocks:
- timestamps that are a combination of physical and logical time
- maximum allowable offset defaults to 500 ms
- HLCs provide causality tracking through their logical component upon each inter-node exchange. The most important of these is a lease disjointness invariant similar to that in Spanner: for each Range, each lease interval is disjoint from every other lease interval. This is enforced on cooperative lease handoff with causality transfer through the HLC and is enforced on non-cooperative lease acquisition through a delay equal to the maximum clock offset between lease intervals
- Strictly monotonic timestamp allocation ensures that two causally dependent transactions originating from the same node are given timestamps that reflect their ordering in real time.
- Uncertainty Intervals:
- CRDB does not support strict serializability because there is no guarantee that the ordering of transactions touching disjoint key sets will match their ordering in real time. In practice, this is not a problem for applications unless there is an external low-latency communication channel between clients that could potentially impact activity on the DBMS.
- CRDB satisfies single-key linearizability for reads and writes.
- Transaction can have earlier timestamp, but its not earlier in reality: if transaction sees future key within uncertainty interval, it will perform an uncertainty restart
- Behavior under Clock Skew: If any node exceeds the configured maximum offset by more than 80% compared to a majority of other nodes, it self-terminates
- 如果有一个捣蛋鬼node时间晚了一个小时,也不自杀,该怎么半?certificate被用于验明正身
- https://www.cockroachlabs.com/blog/living-without-atomic-clocks/
- strongest guarantee of consistency called “external consistency”. To confuse things further, this is what folks interchangeably refer to as “linearizability” or “strict serializability”: 顺序发生的[T1,T2],T2后执行,但是拿着更早的timestamp。回看历史的时候就认为T2先执行(Note that this can only happen when the two transactions access a disjoint set of keys.)
- 如果T1 T2 有相同key,那么它们肯定在clock offset前被检测出来
- Spanner选择等待7ms, 7ms内T2肯定会到. 但让所有操作等7ms并不实际,最新研究可以减少到1ms
- 如果没有相同key, CRDB认为这个情况无所谓
- Spanner (TrueTime) provides linearizability, CockroachDB only goes as far as to claim serializability
- Spanner always waits after writes, CockroachDB sometimes retries reads.
- 虽然CockroachDB不认为linearizability很重要,但commit timestamp很重要。它必须要比所有nodes时间晚,否则它可能读不到already-committed data - an unacceptable breach of consistency
- Spanner选择当前TrueTime即可满足当前committed transaction已经在7ms前完成
- CockroachDB makes use of a “causality token”, which is just the maximum timestamp encountered during a transaction. It’s passed from one actor to the next in a causal chain, and serves as a minimum timestamp for successive transactions to guarantee that each has a properly ordered commit timestamp.
- When CockroachDB starts a transaction, it chooses a provisional commit timestamp based on the current node’s wall time. It also establishes an upper bound on the selected wall time by adding the maximum clock offset for the cluster
\[commit timestamp, commit timestamp + maximum clock offset]. This time interval represents the window of uncertainty. 当碰到比自己晚的timestamp,则uncertainty restart: bumping the provisional commit timestamp just above the timestamp encountered,但是不用改上限 -- Transactions reading constantly updated data from many nodes may be forced to restart multiple times, though never for longer than the uncertainty interval, nor more than once per node. - If it’s unlucky, the read may have to be retried more than once. There is an upper limit on how many retries can occur based on how clocks are synchronized. For NTP, this could be 250ms, so even the most unlucky transactions won’t have to retry for more than 250ms for clock-related reasons.
- SQL
- Primary index is keyed on primary key. Secondary indexes are keyed on index key.
- Vectorized execution engine: data from disk is transposed from row to column format as it is being read from CRDB’s KV layer, and transposed again from column to row format right before it is sent back to the end user. The overhead of this process is minimal.
- Schema Changes: schema change becomes a sequence of incremental changes. In this protocol, the addition of a secondary index requires two intermediate schema versions between the initial and final ones to ensure that the index is being updated on writes across the entire cluster before it becomes available for reads.
- Lessons Learned
- Raft
- Reducing Chatter: Too many heartbeats for a deployment of thousands of consensus groups (one per Range)
- combine heartbeat messages into one per node (not one per-RPC)
- pause heartbeat from Raft groups with no recent write activity
- Joint Consensus: rebalancing replicas across regions will lose availability during single region outage. (temporarily replicas becomes 2 or 4)
- In Joint Consensus, an intermediate configuration exists, but requires instead the quorum of both the old and new majority for writes.
- Removal of Snapshot Isolation 很难简单的实现
- The only safe mechanism to enforce strong consistency under snapshot isolation is pessimistic locking, via the explicit locking modifiers FOR SHARE and FOR UPDATE on queries. To guarantee strong consistency across concurrent mixed isolation levels, CRDB would need to introduce pessimistic locking for any row updates, even for SERIALIZABLE transactions
- Multi Version: Propose the effect of request to Raft, not the request itself
- Related Work
- Spanner: Spanner [4, 17] is a SQL system that provides the strongest isolation level, strict serializability [30]. It achieves this by acquiring read locks in all read-write transactions and waiting out the clock uncertainty window (the maximum clock offset between nodes in the cluster) on every commit. CRDB’s transaction protocol is significantly different from Spanner’s; it uses pessimistic write locks, but otherwise it is an optimistic protocol with a read refresh mechanism that increases the commit timestamp of a transaction if it observes a conflicting write within the clock uncertainty window. This approach provides serializable isolation and has lower latency than Spanner’s protocol for workloads with low contention. It may require more transaction retries for highly contended workloads, however, and for this reason future versions of CRDB will include support for pessimistic read locks. Note that Spanner’s protocol is only practical in environments where specialized hardware is available to bound the uncertainty window to a few milliseconds. CRDB’s protocol functions in any public or private cloud.
- TiDB, NuoDB vs CRDB: these systems are not optimized for geo-distributed workloads and only support snapshot isolation
- SQL Client sends a query to your cluster.
- Load Balancing routes the request to CockroachDB nodes in your cluster, which will act as a gateway.
- Gateway is a CockroachDB node that processes the SQL request and responds to the client.
- Generate SQL physical plan. For example, the SQL executor converts
INSERTstatements intoPut()operations. TxnCoordSenderperforms a large amount of the accounting and tracking for a transaction, including:- Accounts for all keys involved in a transaction. This is used, among other ways, to manage the transaction's state.
- Packages all key-value operations into a
BatchRequest, which are forwarded on to the node'sDistSender.
- DistSender dismantles the initial
BatchRequestby taking each operation and finding which physical machine should receive the request for the range—known as the range's leaseholder. TheDistSenderthen waits to receive acknowledgments for all of its write operations, as well as values for all of its read operations. - Leaseholder is a CockroachDB node responsible for serving reads and coordinating writes of a specific range of keys in your query.
- write intents for a key: these are provisional, uncommitted writes that express that some other concurrent transaction plans to write a value to the key.
- the new transaction attempts to "push" the write intent's transaction by moving that transaction's timestamp forward (i.e., ahead of this transaction's timestamp); however, this only succeeds if the write intent's transaction has become inactive.
- 总之就是比timestamp,先到先执行,或者尝试把前头的transaction推前,如果自己插队了就自我中止,否则只好等着
- leasholder当然有最新的数据供read,但是其它node未必
- Raft leader is a CockroachDB node responsible for maintaining consensus among your CockroachDB replicas.
- The gateway node's
DistSenderaggregates commit acknowledgments from all of the write operations in theBatchRequest, as well as any values from read operations that should be returned to the client. - DistSender 检查timestamp是否被push,如果是则read refresh to see if any values it needed have been changed,如果改变了就重来
- 只有所有operation成功且通过check才会commit. TxnCoordSender 开始异步清理之中生成的write intent,并convert all write intents to fully committed values
- 每个用户独享SQL Pod
- Storage pod被共享,EBS is the block storage system
touch on security, alerting, monitoring, and access. For example, "how do you keep CRDB running?"
Access: SSO for human, TLS public root certificate for SQL client with password
- Multiple disks/SSDs per node: not one node per disk
- At least 3 availability zones: spread nodes evenly on each zone
- At least 3 regions
- Node越大越稳定, node越小failure影响越小
- Storage
- /datastore及/log用独立的volume
- Security
- A certificate authority (CA) certificate and key, used to sign all of the other certificates.
- A separate certificate and key for each node in your deployment, with the common name
node. A separate certificate and key for each client and user you want to connect to your nodes, with the common name set to the username. The default user is
root.- Load Balancing: HAproxy with keepalived
- Clock synchronization
- While serializable consistency is maintained regardless of clock skew, skew outside the configured clock offset bounds can result in violations of single-key linearizability between causally dependent transactions. It's therefore important to prevent clocks from drifting too far by running NTP or other clock synchronization software on each node.
TiDB
https://github.com/pingcap/docs/blob/7eb32c7363e62bbef787e7bf674924b95bc1af37/transaction-isolation-levels.md TiDB implements Snapshot Isolation (SI) consistency, which it advertises as
REPEATABLE-READThe main purpose for TiKV to use LSM-tree instead of B-tree as its underlying storage engine is because using cache technology to promote read performance is much easier than promote write performance.
Distribute single file to 10k servers using DHT
Consistent hash
Think how node join/leave: 把一个环切成若干段,加入一个新节点时就多加一个段点,新节点负责该点到之前点的数据;后面k-1个节点都需要复制这个段的数据 (replica is k)
etcd
etcd is designed to reliably store infrequently updated data and provide reliable watch queries. etcd exposes previous versions of key-value pairs to support inexpensive snapshots and watch history events (“time travel queries”). A persistent (B+ tree), multi-version, concurrency-control data model is a good fit for these use cases.
Deletion is adding a tombstone
Each transaction/ keyspace modification will create a revision. The key of key-value pair is a 3-tuple (major, sub, type). Major is the store revision holding the key. Sub differentiates among keys within the same revision. The value of the key-value pair contains the modification from previous revision, thus one delta from previous revision. The b+tree is ordered by key in lexical byte-order. Ranged lookups over revision deltas are fast; this enables quickly finding modifications from one specific revision to another.
Deletion is adding a tombstone
Each transaction/ keyspace modification will create a revision. The key of key-value pair is a 3-tuple (major, sub, type). Major is the store revision holding the key. Sub differentiates among keys within the same revision. The value of the key-value pair contains the modification from previous revision, thus one delta from previous revision. The b+tree is ordered by key in lexical byte-order. Ranged lookups over revision deltas are fast; this enables quickly finding modifications from one specific revision to another.
Kafka
How is Kafka's durability?- Kafka is not using directly I/O, it would return after writing into page cache (rather than maintain as much as possible in-memory and flush it all out to the filesystem in a panic when we run out of space, we invert that. All data is immediately written to a persistent log on the filesystem without necessarily flushing to disk. In effect this just means that it is transferred into the kernel's pagecache): https://kafka.apache.org/documentation/#design
- Data loss could be minimum as Kafka only returns after replications get done
Prometheus
Prometheus needs manual management for scalability: https://prometheus.io/docs/introduction/faq/#i-was-told-prometheus-doesnt-scale
Ideal Architecture
Service level design
- What is the product use scenario, what need to trade-off? What would piss of our users?
- Do we need storage? Uber driver location does not need storage
- How to scale storage? Sharding and replication
- how to find the sharded storage? Needs to index them somewhere
- Is AppServer stateless? Otherwise, why?
- Principle: workers only ask for tasks it can handle, add one scheduler to coordinate tasks assignment. e.g., One worker can handle Ohio state, but another work can only handle NYC task
- Transactions. Cut super large transactions into stages/more services; add a watcher to record transaction progress
- Needs locality for high performance? How high is the locality needs? Can we move these localities/business logic into storage layer?
- How about join operations between workers? Has to cut it into multiple stages, like Big Data?
- Routing: always route to nearest DC; always determine locality as early as possible
Host level design
Extreme performant Linux web service:- How to exhaust multi-processor's performance:
- multi-processing vs multi-threading: depends on how many resources are shared
- Python asyncio: ensure each operation is asynchronous, then spawn 32 processes
- Goroutines: pro for developer velocity, forget about concurrency cost, just do synchronous operations
- Threading model: N:1, kernel schedules at process level, process schedules its threads at its own discretion; 1:1, kernel schedules at thread level. Hybrid model
- Linux web programing: multi-processing using epoll; parent process dispatch accepted fd
- fork() is dangerous if parent has a mysql connection fd: child could stop it from being closed
Consistency: All clients see the same most recent write or error
Availability: All reads contain data without error, but may not be most recent
Partition Tolerance: The system works despite network failures
分布式系统
- https://eng.uber.com/intro-to-ringpop/, drawbacks of masterless
- No master, then each worker advertise itself then misconfigured worker will pollute the traffic
- The design meant that there were normally 3 network hops & 2 processes between the client and the service. This coupled with the language choice led to high P99s close to 100ms
- Service Discovery: what is Consul? etcd? zookeeper?
- 分布式系统常用思想和技术总结
- Riak
- https://coolshell.cn/
- 分布式系统的事务处理
- 2PC: 如果第一阶段完成后,参与者在第二阶段timeout,那么数据结点会进入“不知所措”的状态,这个状态会block住整个事务
- 3PC: 在询问的时候并不锁定资源,除非所有人都同意了,才开始锁资源
- timeout is the nightmare of all distributed state machine
- 高可用系统
- https://en.wikipedia.org/wiki/State_machine_replication
ACID

主节点和只读节点之间是 Active-Active 的 Failover 方式,计算节点资源得到充分利用,由于使用共享存储,共享同一份数据

- 数据库事务原子性、一致性是怎样实现的?
- MVCC是一种后验性的,读不阻塞写,写也不阻塞读,等到提交的时候才检验是否有冲突,由于没有锁,所以读写不会相互阻塞,从而大大提升了并发性能
PolarDB
RDS Provisioned IOPS is ~ 100k IOPS
阿里云 PolarDB 和 Amazon Aurora 的一个共同设计哲学就是,放弃了通用分布式数据库 OLTP 多路并发写的支持,采用一写多读的架构设计
主节点和只读节点之间是 Active-Active 的 Failover 方式,计算节点资源得到充分利用,由于使用共享存储,共享同一份数据
PolarDB 的设计思想有几个大的革新。一是通过重新设计特定的文件系统来存取 Redo log 这种特定的 WAL I/O 数据,二是通过高速网络和高效协议将数据库文件和 Redo log 文件放在共享存储设备上,避免了多次长路径 I/O 的重复操作,相比较 Binlog 这种方式更加巧妙
主节点和只读节点之间采用 Active-Active 的 Failover 方式,提供 DB 的高可用服务。DB 的数据文件、redolog 等通过 User-Space 用户态文件系统,经过块设备数据管理路由,依靠高速网络和 RDMA 协议传输到远端的 Chunk Server。同时 DB Server 之间仅需同步 Redo log 相关的元数据信息。Chunk Server 的数据采用多副本确保数据的可靠性,并通过 Parallel-Raft 协议保证数据的一致性。
Shared Disk 架构
PolarDB 采用 Shared Disk 架构,其根本原因是上述的计算与存储分离的需要。逻辑上 DB 数据都放在所有 DB server 都能够共享访问的数据 chunk 存储服务器上。而在存储服务内部,实际上数据被切块成 chunk 来达到通过多个服务器并发访问 I/O 的目的
物理 Replication
我们知道,MySQL Binlog 记录的是 Tuple 行级别的数据变更。而在 InnoDB 引擎层,需要支持事务 ACID,也维持了一份 Redo 日志,存储的是基于文件物理页面的修改。这样 MySQL 的一个事务处理默认至少需要调用两次 fsync() 进行日志的持久化操作,这对事务处理的系统响应时间和吞吐性能造成了直接的影响。尽管 MySQL 采用了 Group Commit 的机制来提升高并发下的吞吐量,但并不能完全消除 I/O 瓶颈。
此外,由于单个数据库实例的计算和网络带宽有限,一种典型的做法是通过搭建多个只读实例分担读负载来实现 Scale out。PolarDB 通过将数据库文件以及 Redolog 等存放在共享存储设备上,非常讨巧的解决了只读节点和主节点的数据 Replication 问题。由于数据共享,只读节点的增加无需再进行数据的完全复制,共用一份全量数据和 Redo log,只需要同步元数据信息,支持基本的 MVCC,保证数据读取的一致性即可。这使得系统在主节点发生故障进行 Failover 时候,切换到只读节点的故障恢复时间能缩短到 30 秒以内。系统的高可用能力进一步得到增强。而且,只读节点和主节点之间的数据延迟也可以降低到毫秒级别。
从并发的角度来看,使用 Binlog 复制现在只能按照表级别并行复制,而物理复制只按照数据页维度,粒度更细,并行效率更加高。
最后一点,引入 Redolog 来实现 Replication 的好处是,Binlog 是可以关闭来减少对性能的影响,除非需要 Binlog 来用于逻辑上的容灾备份或者数据迁移。
总之,在 I/O 路径中,通常越往底层做,越容易和上层的业务逻辑和状态解耦而降低系统复杂度。而且这种 WAL Redo log 大文件读写的 I/O 方式也非常适用于分布式文件系统的并发机制,为 PolarDB 带来并发读性能的提高。
高速网络下的 RDMA 协议
RDMA 通常是需要有支持高速网络连接的网络设备(如交换机,NIC 等),通过特定的编程接口,来和 NIC Driver 进行通讯,然后通常以 Zero-Copy 的技术以达到数据在 NIC 和远端应用内存之间高效率低延迟传递,而不用通过中断 CPU 的方式来进行数据从内核态到应用态的拷贝,极大的降低了性能的抖动,提高了整体系统的处理能力。
Snapshot 物理备份
Snapshot 是一种流行的基于存储块设备的备份方案。其本质是采用 Copy-On-Write 的机制,通过记录块设备的元数据变化,对于发生写操作的块设备进行写时复制,将写操作内容改动到新复制出的块设备上,来实现恢复到快照时间点的数据的目的。Snapshot 是一个典型的基于时间以及写负载模型的后置处理机制。也就是说创建 Snapshot 时,并没有备份数据,而是把备份数据的负载均分到创建 Snapshot 之后的实际数据写发生的时间窗口,以此实现备份、恢复的快速响应。PolarDB 提供基于 Snapshot 以及 Redo log 的机制,在按时间点恢复用户数据的功能上,比传统的全量数据结合 Binlog 增量数据的恢复方式更加高效。
Amazon Aurora
storage is independent of computing
The Aurora shared storage architecture makes your data independent from the DB instances in the cluster. For example, you can add a DB instance quickly because Aurora doesn't make a new copy of the table data. Instead, the DB instance connects to the shared volume that already contains all your data. You can remove a DB instance from a cluster without removing any of the underlying data from the cluster. Only when you delete the entire cluster does Aurora remove the data.
As a result, all Aurora Replicas return the same data for query results with minimal replica lag. This lag is usually much less than 100 milliseconds after the primary instance has written an update. Replica lag varies depending on the rate of database change. That is, during periods where a large amount of write operations occur for the database, you might see an increase in replica lag.
既然主从都用一样的storage: cluster volume,为何主从之间存在replication lag?
Because Aurora Replicas read from the same cluster volume as the writer DB instance, the
ReplicaLag metric has a different meaning for an Aurora PostgreSQL DB cluster. The ReplicaLag metric for an Aurora Replica indicates the lag for the page cache of the Aurora Replica compared to that of the writer DB instance.因为它使用了一个独立的page cache process,而不是直接从disk读。猜想: writer instance的操作会直接replicate到reader instance page cache
In the unlikely event of a database failure, the page cache remains in memory, which keeps current data pages "warm" in the page cache when the database restarts. This provides a performance gain by bypassing the need for the initial queries to execute read I/O operations to "warm up" the page cache.
MicroServices
Coding
屏蔽关键词,及替换词{"o": [], "1": ["l"]}:TRIE tree
System Design
design URL shorter
实现聊天室,各种功能
订阅:
评论 (Atom)